Refactoring is a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior.
Its heart is a series of small behavior preserving transformations. Each transformation (called a “refactoring”) does little, but a sequence of these transformations can produce a significant restructuring. Since each refactoring is small, it's less likely to go wrong. The system is kept fully working after each refactoring, reducing the chances that a system can get seriously broken during the restructuring.

When a software system is successful, there is always a need to keep enhancing it, to fix problems and add new features. After all, it's called software for a reason! But the nature of a code-base makes a big difference on how easy it is to make these changes. Often enhancements are applied on top of each other in a manner that makes it increasingly harder to make changes. Over time new work slows to a crawl. To combat this change, it's important to refactor code so that added enhancements don't lead to unnecessary complexity.
Refactoring isn't a special task that would show up in a project plan. Done well, it's a regular part of programming activity. When I need to add a new feature to a codebase, I look at the existing code and consider whether it's structured in such a way to make the new change straightforward. If it isn't, then I refactor the existing code to make this new addition easy. By refactoring first in this way, I usually find it's faster than if I hadn't carried out the refactoring first.
Once I've done that change, I then add the new feature. Once I've added a feature and got it working, I often notice that the resulting code, while it works, isn't as clear as it could be. I then refactor it into a better shape so that when I (or someone else) return to this code in a few weeks time, I won't have to spend time puzzling out how this code works.
When modifying a program, I'm often looking elsewhere in the code, because much of what I need to do may already be encoded in the program. This code may be functions I can easily call, or hidden inside larger functions. If I struggle to understand this code, I refactor it so I won't have to struggle again next time I look at it. If there's some functionality buried in there that I need, I refactor so I can easily use it.
When I wrote the first edition of Refactoring, back in the late 90's, there were few automated tools that supported Refactoring. Now many languages have IDEs which automate many common refactorings. These are a really valuable part of my toolkit allowing me to carry out refactoring faster. But such tools aren't essential - I often work in programming languages without tool support, in which case I rely on taking small steps, and using frequent testing to detect mistakes.
The primary content of this site is the online catalog of refactorings. This lists the refactorings in the second edition, together with summary information about the refactorings.
 To learn more about
refactoring, the natural starting point is my refactoring
book, now in its second edition. I wrote the original edition in
1997-9 when Refactoring was a little-known technique. When I updated it
eighteen years later, refactoring had become a regular tool for any
skilled programmer. However new people regularly enter our profession
and need to learn about refactoring. This book helps them to learn, and
for experienced developers to pass on their skills.
To learn more about
refactoring, the natural starting point is my refactoring
book, now in its second edition. I wrote the original edition in
1997-9 when Refactoring was a little-known technique. When I updated it
eighteen years later, refactoring had become a regular tool for any
skilled programmer. However new people regularly enter our profession
and need to learn about refactoring. This book helps them to learn, and
for experienced developers to pass on their skills.
The examples in the second edition are in JavaScript, but the refactorings are applicable in any language. With the original books (whose examples were in Java) many developers found it straightforward to take the examples and apply them to whatever languages they use.
If you have the book you can access the web edition of the book, which is the canonical edition. It includes several refactorings not in the book, as well as an expanded example.
In the book, I make the following definition of “refactoring”
noun: a change made to the internal structure of software to make it easier to understand and cheaper to modify without changing its observable behavior
verb: to restructure software by applying a series of refactorings without changing its observable behavior.
Refactoring isn't another word for cleaning up code - it specifically defines one technique for improving the health of a code-base. I use “restructuring” as a more general term for reorganizing code that may incorporate other techniques.
My main website contains more of my writing on refactoring. In particular it contains several longer examples, mostly written just before the second edition of the book:
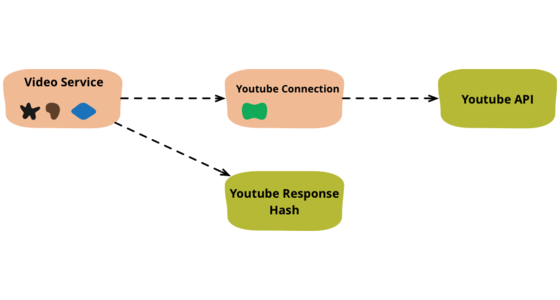
When I write code that deals with external services, I find it valuable to separate that access code into separate objects. Here I show how I would refactor some congealed code into a common pattern of this separation.
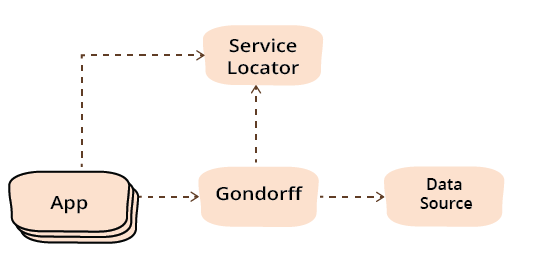
As a program grows in size it's important to split it into modules, so that you don't need to understand all of it to make a small modification. Often these modules can be supplied by different teams and combined dynamically. In this refactoring essay I split a small program using Presentation-Domain-Data layering. I then refactor the dependencies between these modules to introduce the Service Locator and Dependency Injection patterns. These apply in different languages, yet look different, so I show these refactorings in both Java and a classless JavaScript style.
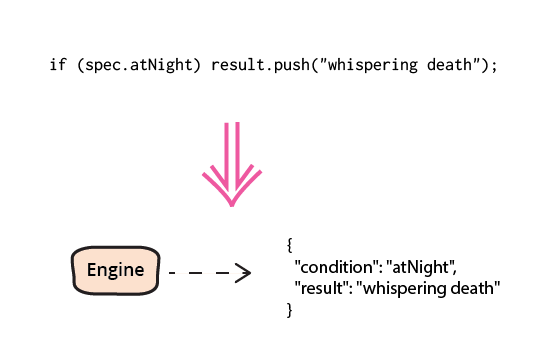
Most of our software logic is written in our programming languages, these give us the best environment to write and evolve such logic. But there are circumstances when it's useful to move that logic into a data structure that our imperative code can interpret - what I refer to as an adaptive model. Here I'll show some product selection logic in JavaScript and show how it can be refactored to a simple production rule system encoded in JSON. This JSON data allows us to share this selection logic between devices using different programming languages and to update this logic without updating the code on these devices.
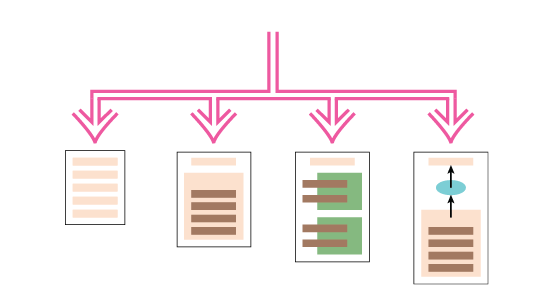
The simple example of calculating and formatting a bill for a video store opened my refactoring book in 1999. If done in modern JavaScript, there are several directions you could take the refactoring. I explore four here: refactoring to top level functions, to a nested function with a dispatcher, using classes, and transformation using an intermediate data structure.
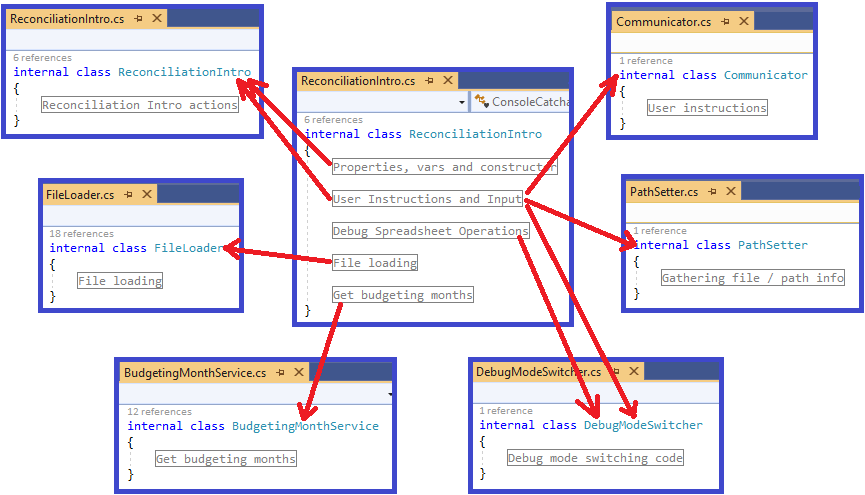
In this article I walk through a set of refactorings from a real code base. This is not intended to demonstrate perfection, but it does represent reality.
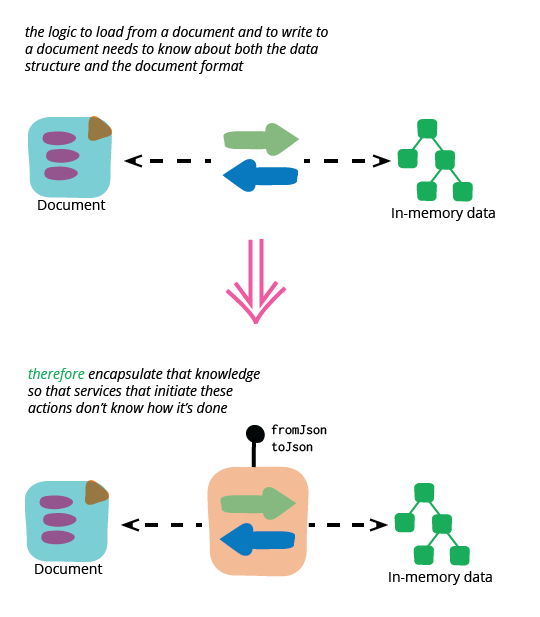
Much modern web server code talks to upstream services which return JSON data, do a little munging of that JSON data, and send it over to rich client web pages using fashionable single page application frameworks. Talking to people working with such systems I hear a fair bit of frustration of how much work they need to do to manipulate these JSON documents. Much of this frustration could be avoided by encapsulating a combination of loading strategies.

The loop is the classic way of processing collections, but with the greater adoption of first-class functions in programming languages the collection pipeline is an appealing alternative. In this article I look at refactoring loops to collection pipelines with a series of small examples.

If you're validating some data, you usually shouldn't be using exceptions to signal validation failures. Here I describe how I'd refactor such code into using the Notification pattern.
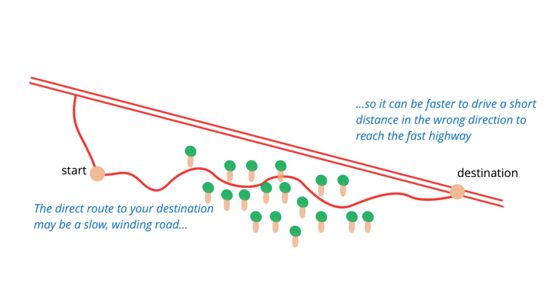
A simple example of how it can be easier to make a change by first refactoring the code to make the change easy.
